- FAQ по индексированию файлов PDF
- Как искать файлы PDF в Google
- PDF-файлы могут даже отображаться в избранных фрагментах
- Другие типы файлов, индексируемые Google
В недавнем видеовстрече Google Джон Мюллер подтвердил, что они индексируют файлы PDF точно так же, как и на любой другой веб-странице . Джон Мюллер также дал понять, почему такой файл PDF не может быть проиндексирован, несмотря на это.
В Google Hangout был задан следующий вопрос 18:48 :
Вопрос: Я не могу получить много своих PDF-файлов, проиндексированных на страницах моего продукта. Должен ли я просто добавить контент на вкладку своего продукта, чтобы он был в обоих местах? Приведет ли это к проблемам с дублированием и есть ли идея, почему они не будут индексироваться?
Джон Мюллер : В общем, мы индексируем PDF-файлы так же, как и другие обычные страницы на сайте. Что, вероятно, произойдет с PDF-файлами, так это то, что мы не так часто их обновляем, как обычные HTML-страницы, поскольку предполагаем, что PDF-файлы остаются стабильными. Но это не похоже на твою проблему. Что касается индексации файлов PDF, если мы увидим ссылки на эти страницы, мы попытаемся проиндексировать эти страницы, чтобы включить их в результаты поиска.
Джон Мюллер : Итак, если мы не можем проиндексировать эти страницы, то либо у нас возникают проблемы с поиском ссылок на эти файлы PDF, возможно, из-за того, что их трудно найти на веб-сайте, либо, возможно, они не находятся в статическом HTML, либо у них есть ссылка nofollow или что-то в этом роде. Или, может быть, мы говорим, что у нас уже достаточно контента, проиндексированного с вашего сайта. Мы еще не готовы добавить значительную партию контента. Таким образом, мы не можем гарантировать, что будем индексировать весь контент на веб-сайте, что означает, что для некоторых веб-сайтов в некоторых ситуациях у нас может быть отсечение, и мы говорим, что уже проиндексировали много контента с этого веб-сайта. Мы будем продолжать сканировать больше контента с этого веб-сайта, и если мы найдем что-то действительно интересное, мы также включим это в индекс. Возможно, эти PDF-файлы - это контент, который мы просмотрели, или контент, на который у нас не было времени посмотреть с веб-сайта.
Джон Мюллер : Если в тех PDF-файлах есть важный контент, который вам нужно проиндексировать, возможно, стоит включить его на страницу продукта. Таким образом, людям не нужно скачивать PDF-файл, чтобы увидеть этот контент. Так что, если это важно, возможно, разместите это прямо на странице. Если это более вспомогательный контент, например, справочный материал, на который люди могут захотеть посмотреть, но не нужно оценивать его отдельно, тогда, возможно, будет хорошо просто ссылаться на страницы вашего продукта.
Вы можете просмотреть соответствующую часть обсуждения ниже:
FAQ по индексированию файлов PDF
Это не первый раз, когда возникает проблема индексации PDF-файлов. В Центральная запись блога для веб-мастеров Еще в сентябре 2011 года Гари Иллис из Google ответил на несколько вопросов об индексации PDF, которые мы кратко изложим ниже:
В общем, да, Google сканирует PDF-файлы, если они не защищены паролем или не зашифрованы. Если текст встроен в виде изображений, Google может обрабатывать эти изображения для извлечения текста. Общее правило заключается в том, что если вы можете копировать \ вставлять текст из документа PDF, Google должен иметь возможность выполнять поиск содержимого PDF и индексировать его.
Изображения в файлах PDF не индексируются (по состоянию на 2011 год).
Ссылки обрабатываются так же, как ссылки на веб-страницах. Они передают PageRank и другие сигналы индексации и будут отслеживаться при сканировании. Невозможно «nofollow» ссылки в файле PDF.
Вы должны добавить «X-Robots-Tag: noindex» в заголовок HTTP, используемый для обслуживания файла. Если они уже проиндексированы, то реализованный заголовок заставит их выпадать со временем. Кроме того, вы можете использовать Инструмент для удаления URL ,
Файлы PDF могут ранжироваться аналогично веб-страницам.
Google использует метаданные заголовка в файле и якорный текст ссылок, указывающих на файл PDF. Google рекомендует установить оба.
Как искать файлы PDF в Google
Как искать файлы PDF в Google
- Используйте оператор filetype для поиска файлов PDF
Если вы хотите искать PDF-файлы в Google, вы можете использовать оператор «filetype:».
Для поиска файлов PDF по поисковому запросу «SEO PDF» введите следующее:
- Тип файла: pdf SEO PDF
- Затем нажмите «Поиск Google».
- Страница результатов SERP показывает PDF в верхнем индексе слева от каждого результата
Вы можете увидеть скриншот результатов на скриншоте.
PDF-файлы могут даже отображаться в избранных фрагментах
17 января 2019 г. Кевин Индиг сообщил в Твиттере что Google теперь извлекает избранные фрагменты из файлов PDF.
Я попробовал приведенный пример, и он работал до 26 января. Вы можете увидеть скриншот ниже:
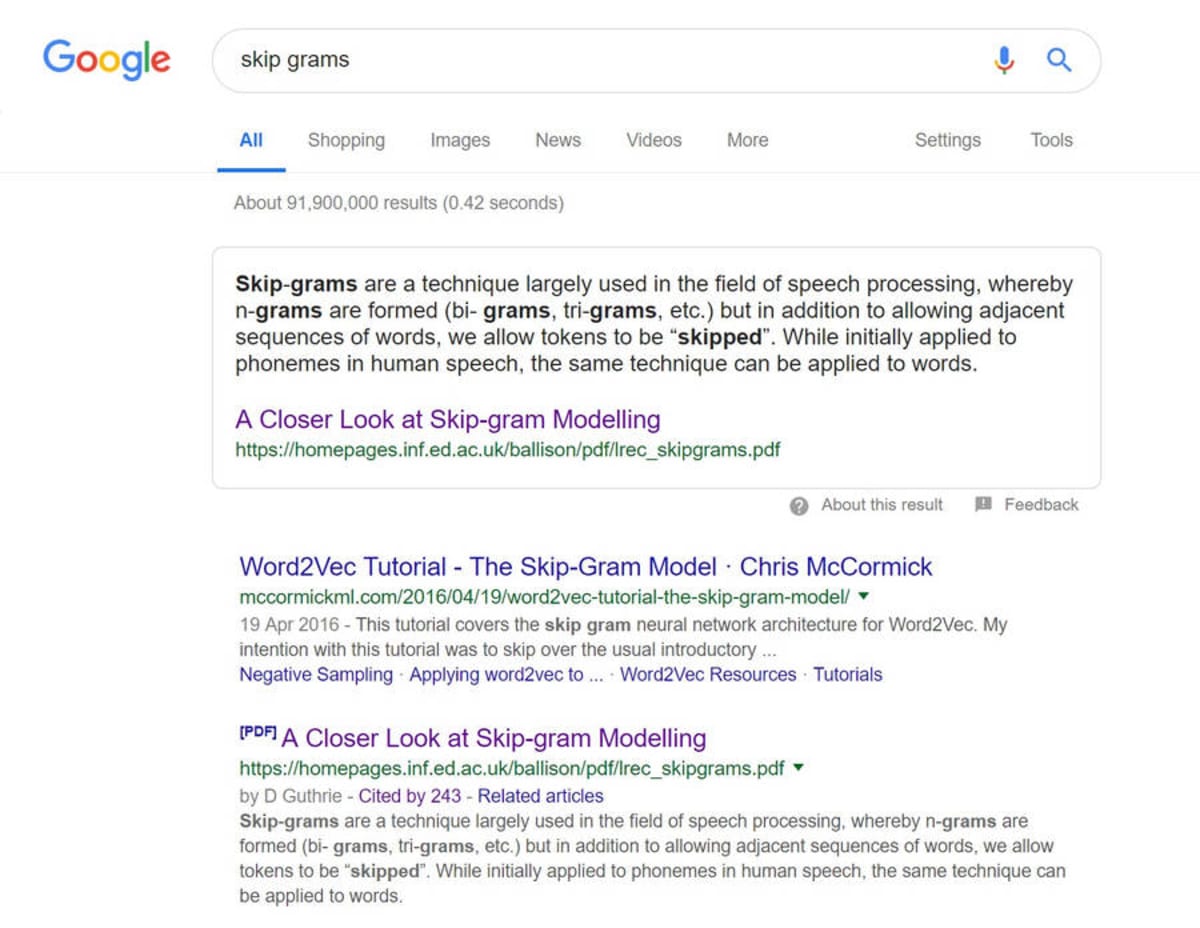
Показанный фрагмент из PDF, отображаемый в Google. © Вебмастер
Вы можете поспорить, что многие специалисты по SEO теперь будут оптимизировать свои PDF для поисковых систем.
Другие типы файлов, индексируемые Google
PDF - это лишь один из большого количества типов файлов, которые могут быть проиндексированы Google.
Google может индексировать содержимое большинства типов страниц и файлов, включая Adobe Flash, документы Microsoft, такие как Excel и Docs, Rich Text Format, документы OpenOffice, PowerPoint и различные языки программирования.
Вы можете найти полный список индексируемые файлы здесь ,
Похожие
Как использовать Google Webmaster Tools для SEO анализа... Google для веб-мастеров (GWT) позволяют веб-мастерам взглянуть на то, как робот Google просматривает и сканирует ваш сайт. Это отличный инструмент для SEO, и вы можете зарегистрироваться бесплатно. Google Webmaster Tool связывает вашу учетную запись Google с вашими сайтами, так что вы можете управлять всеми сайтами под одной крышей. Google Webmaster Tool показывает количество показов, которые вы получали каждый день, клики, которые вы получили от этих показов, увеличение или уменьшение рейтинга SEO: Как мне начать позиционировать свой сайт в Google?
Всем компаниям нужен сайт, и все сайты должны быть видны в поисковых системах. Это реальность, которая привлекает все больше и больше людей к изучению того, что такое SEO и как они могут начать позиционировать свой сайт в Google. Есть несколько ключей для SEO стратегия работает с самого начала , Но сначала необходимо знать, каковы цели сети, ее ключевые слова и возможная аудитория. В отличие Платные ссылки и SEO: будет ли Google панализировать ваш сайт?
... вания вашего сайта в SEPR; но только если у вас есть хорошие средства, чтобы потратить их на SEO-кампанию. Тем не менее, это против естественного SEO, который влияет органические результаты поиска , И это несправедливо по отношению к другим владельцам сайтов, которые либо не имеют такого большого бюджета на SEO, либо верят в естественное SEO. Эмоции: как люди регулируют их и почему некоторые люди не могут
Возьмите следующий сценарий. Вы приближаетесь к концу напряженного рабочего дня, когда комментарий от вашего босса уменьшает то, что осталось от вашего истощающегося терпения. Вы поворачиваетесь с красным лицом к источнику вашего негодования. Тогда вы останавливаетесь, размышляете и решаете не выражать свое недовольство. В конце концов, сдвиг почти закончился. Возможно, это не самый захватывающий сюжет, но он показывает, как мы, люди, можем SEO дизайн сайта Хартфордшир
Найти в Google! Поисковая оптимизация! Теперь это фраза на устах многих людей в минуту. В мире «поиска» мы все знаем, что «чтобы быть найденным» нам нужно проанализировать это до смерти, чтобы убедиться, что мы появляемся в поисковых системах, чтобы гарантировать, что мы привлекаем веб-пользователей Как малые предприятия могут видеть большие результаты с основополагающим SEO
Независимо от того, начинаете ли вы свой путь поисковой оптимизации (SEO) или уже много лет, есть большая вероятность, что какая-то часть вашего сайта может быть улучшена. На самом деле, из сотен Дублированный контент: как насчет SEO?
Если на вашем веб-сайте несколько страниц с одинаковым содержанием, это может повлиять на вашу ценность для SEO. Это также относится к случаям, когда разные сайты используют один и тот же контент. Но как насчет SEO? В этом блоге я расскажу, может ли повредить дублирующийся контент, как вы должны с этим бороться и как это повлияет на SEO. Уникальное значение против уникальный контент Важность Google+ в конкурсе SEO
... вой части тоже «Google+ SEO для бизнеса» Мы уже показали, почему имеет смысл включать Google+ в дополнение к Facebook в качестве социальной сети в поисковую оптимизацию, особенно для малых и средних компаний. Каков наилучший способ продолжить? Шаг за шагом к профилю компании в Google+ Что на Facebook фан-страница, есть в Google+ с ноября 2011 года, Google + - страница для компаний. SEO мертв, контент жив
Возможно, вы слышали заголовки в течение 2013 года: « SEO мертв? » Эксперты по поисковому маркетингу все еще работают, чтобы выяснить, как изменения алгоритма Google наказание
Штрафы Google - это меры, принятые Google для борьбы со спамом . Целью Google Штрафов является предоставление операторам сайтов, которые нарушают качество Руководство для веб-мастеров нарушил, накажи. Google хочет убедиться, что его собственный поисковый индекс всегда может предложить пользователям наилучшие результаты поиска и отодвинуть назад результаты Как использовать Google Keyword Planner Tool для SEO |
... Google для ключевых слов были первыми, что профессионалы SEO посещали, когда исследовали ключевые слова для SEO, поскольку это было надежно, бесплатно и было инструментом Google. Но в конце августа 2013 года Google снял его, и его место занял инструмент Google Keyword Planner, который представлял собой комбинацию инструмента подсказки ключевых слов и Оценщика трафика. Это изменение от Google потрясло сообщество SEO, так как не было никакого способа найти тесно связанные термины, ни локальных
Комментарии
Пишете ли вы хороший контент, получаете ли естественные ссылки и делаете ли ваш сайт удобным для пользователя, чтобы попасть на страницу 1?Пишете ли вы хороший контент, получаете ли естественные ссылки и делаете ли ваш сайт удобным для пользователя, чтобы попасть на страницу 1? Пожалуйста, оставьте свои комментарии ниже. Примечание . Мнения, выраженные в этой статье, являются мнением автора, а не обязательно мнением Caphyon, его сотрудников или партнеров. Но как производить контент с качеством, требуемым поисковыми системами Google?
Но как производить контент с качеством, требуемым поисковыми системами Google? Как оптимизировать контент? Ниже мы представляем основные советы. 1. Ключевое слово исследований Первым шагом к созданию контента с потенциалом для получения хорошего позиционирования является поиск по ключевым словам. Есть несколько инструментов для поиска по ключевым словам, но наиболее важным является Планировщик ключевых слов Знаете ли вы, что можно занять место на первой странице Google, когда речь идет о такой популярной теме, как Disney?
Знаете ли вы, что можно занять место на первой странице Google, когда речь идет о такой популярной теме, как Disney? Мой пример поста, который ранжируется на первой странице Google по различным поисковым запросам, связанным с Диснеем, называется: Дисней Список фильмов, которые вы можете скачать бесплатно! Вот хитрость при изучении ранжирования по ключевому слову, относящемуся к очень Мы хотели бы знать, используете ли вы Google Keyword Planner для своего SEO или вы используете другие инструменты?
Мы хотели бы знать, используете ли вы Google Keyword Planner для своего SEO или вы используете другие инструменты? Достаточно ли у вас финансовой взлетно-посадочной полосы, чтобы запустить этот маховик, даже если бы потребовалось несколько месяцев или даже лет, чтобы начать вести значимый трафик или клиентов?
Достаточно ли у вас финансовой взлетно-посадочной полосы, чтобы запустить этот маховик, даже если бы потребовалось несколько месяцев или даже лет, чтобы начать вести значимый трафик или клиентов? У вас есть команды, которые могут заниматься как производством контента, так и технической оптимизацией сайта? Когда вы смотрите на инструменты, как SEMrush для типов поисковых запросов, которые вы хотели бы показать, это жесткая или относительно мягкая конкуренция? Есть ли дублированный контент, были ли заголовки неправильно включены?
Достаточно ли у вас финансовой взлетно-посадочной полосы, чтобы запустить этот маховик, даже если бы потребовалось несколько месяцев или даже лет, чтобы начать вести значимый трафик или клиентов? У вас есть команды, которые могут заниматься как производством контента, так и технической оптимизацией сайта? Когда вы смотрите на инструменты, как SEMrush для типов поисковых запросов, которые вы хотели бы показать, это жесткая или относительно мягкая конкуренция? Могут ли поисковые системы сканировать контент, отображаемый с помощью JavaScript?
Могут ли поисковые системы сканировать контент, отображаемый с помощью JavaScript? Краткий ответ «да» опасен. Этот упрощенный ответ создает много рисков, когда команды разработчиков и разработчики переходят на JavaScript-дизайн без предварительного изучения нюансов. Точнее, Google может сканировать JavaScript в широком смысле, но есть предостережения и ограничения. Сканирование JavaScript не так проверено в бою, как сканирование HTML. Если вы полагаетесь на JavaScript-сканирование Знаете ли вы, что вы можете видеть, сколько посетителей перешли с сайтов каталогов на страницы вашего сайта в системах веб-аналитики, таких как Google Analytics?
Знаете ли вы, что вы можете видеть, сколько посетителей перешли с сайтов каталогов на страницы вашего сайта в системах веб-аналитики, таких как Google Analytics? Я рекомендую вам сравнить этих рефералов до и после того, как вы выполнили оптимизацию в своих списках - если вы добились успеха в своих усилиях, я бы предположил, что вы, вероятно, увидите увеличение числа рефералов! Дальнейшее увеличение продаж Многие компании чрезмерно сосредоточены на том, как они Но как именно они могут определить хороший контент?
Но как именно они могут определить хороший контент? Один из самых эффективных способов - через социальные сигналы. Социальный сигнал определяет, когда контент на странице был прокомментирован, опубликован или добавлен в социальные сети. Это указывает на качество контента из-за того, что плохим контентом редко делятся или любят. 3 способа увеличить авторитет вашей страницы Теперь, когда вы знаете, что такое Page Authority и какие факторы использует Это огромный домен, такой как HuffPo, который, как вы знаете, вряд ли будет опубликован в гостевой статье?
Это огромный домен, такой как HuffPo, который, как вы знаете, вряд ли будет опубликован в гостевой статье? Если вы знакомы с вашим пространством, вы, вероятно, увидите много сайтов, которые вы узнаете и можете отклонить на сайте. Метаданные : Вы можете многое рассказать о сайте по названию и описанию. Получите, какую информацию вы можете. Если вы видите некоторые из ваших целевых ключевых слов, вы можете открыть его! Мой Совершенно секретный Шаг Шесть Экономит Как Google , Bing а также Yahoo даже работа?
Это огромный домен, такой как HuffPo, который, как вы знаете, вряд ли будет опубликован в гостевой статье? Если вы знакомы с вашим пространством, вы, вероятно, увидите много сайтов, которые вы узнаете и можете отклонить на сайте. Метаданные : Вы можете многое рассказать о сайте по названию и описанию. Получите, какую информацию вы можете. Если вы видите некоторые из ваших целевых ключевых слов, вы можете открыть его! Мой Совершенно секретный Шаг Шесть Экономит
Должен ли я просто добавить контент на вкладку своего продукта, чтобы он был в обоих местах?
Приведет ли это к проблемам с дублированием и есть ли идея, почему они не будут индексироваться?
Но как насчет SEO?
Каков наилучший способ продолжить?
Пишете ли вы хороший контент, получаете ли естественные ссылки и делаете ли ваш сайт удобным для пользователя, чтобы попасть на страницу 1?
Но как производить контент с качеством, требуемым поисковыми системами Google?
Но как производить контент с качеством, требуемым поисковыми системами Google?
Как оптимизировать контент?
Знаете ли вы, что можно занять место на первой странице Google, когда речь идет о такой популярной теме, как Disney?
Мы хотели бы знать, используете ли вы Google Keyword Planner для своего SEO или вы используете другие инструменты?